
Machine Learning based Cardiovascular Disease Pattern Prediction Technique for Remote Healthcare Monitoring Systems
Received: 03-May-2023, Manuscript No. AMHSR-23-97704; Editor assigned: 05-May-2023, Pre QC No. AMHSR-23-97704 (PQ); Reviewed: 19-May-2023 QC No. AMHSR-23-97704; Revised: 03-Jul-2023, Manuscript No. AMHSR-23-97704 (R); Published: 10-Jul-2023
Citation: Subhasini SV, et al. Machine Learning based Cardiovascular Disease Pattern Prediction Technique for Remote Healthcare Monitoring Systems. Ann Med Health Sci Res. 2023;13:860-866
This open-access article is distributed under the terms of the Creative Commons Attribution Non-Commercial License (CC BY-NC) (http://creativecommons.org/licenses/by-nc/4.0/), which permits reuse, distribution and reproduction of the article, provided that the original work is properly cited and the reuse is restricted to noncommercial purposes. For commercial reuse, contact reprints@pulsus.com
Abstract
Wearable devices and the various applications of wearable devices are increasing greatly which encourages researchers to focus much on Internet of Medical Things (IoMT). The IoMT is playing a major and considerable role for reducing mortality rates as IoMT is helping diseases pattern well in advance. As we know, the cardiovascular disease threatens us as mortality is relatively high which is observed from the available literature survey. It was noticed from the statistical report that there were relatively high rate of heart diseases registered. The healthcare system is needed for the better cardiovascular diseases prediction techniques, which will help medical practitioners to predict this disease well in advance that will facilitate early prevention, detection, and fruitful treatment to patients. This will save human life and can reduce mortality rate. As we know, machine learning models and the internet of medical things jointly enabled methodologies for supporting healthcare services particularly for cardiovascular disease pattern prediction, classification and accurate diagnosis. It was noticed that there were two IoMT based models proposed recently. They are Bagging- Fuzzy-Gradient Boosting Decision Tree (FGBDT) and Hybrid Random Forest-Linear Model (HRFLM). These two models were implemented and analyzed their performances during training and testing processes in terms of prediction accuracy, precision, sensitivity, specificity, FScore and average processing time (ms) and it was noticed that the Hybrid Random Forest- Linear Model (HRFLM) is performing well in terms of accuracy and time complexity whereas Bagging-Fuzzy-Gradient Boosting Decision Tree (FGBDT) is performing well in terms of precision, sensitivity, specificity and FScore. To maximize classification and prediction accuracy better, this work is proposed an efficient Ensemble Support Vector classifier-Weighted Random Forest called ensemble SVC-WRF (E-SVC-WRF) and implemented for analysis. From the experimental results, it was noticed that the proposed Ensemble Support Vector classifier-Weighted Random Forest called ensemble SVC-WRF (E-SVC-WRF) is performing well as compared with Hybrid Random Forest-Linear Model (HRFLM) and Bagging- Fuzzy-Gradient Boosting Decision Tree (FGBDT) in terms of prediction accuracy, precision, sensitivity, specificity, FScore and average processing time (ms).
Keywords
Cardiovascular diseases; Patterns prediction; Internet of medical things; SVM; Weighted random forest; Machine learning
Introduction
As we know, heart diseases happening due to coronary artery disease, pulse rate issue, blood vessel diseases, arrhythmias issues etc. There were a few common conditions for heart diseases that are high blood pressure, heart failure, heart attack, congenital heart conditions, unstable angina etc. As we know, people calling heart diseases as cardiovascular diseases. The heart disease is also called as Cardiovascular Diseases (CVD).
The cardiovascular diseases CVD refer various reasons and conditions for heart diseases particularly blocks in blood vessel [1]. As blood is blocked by blocks in blood vessels, it causes heart’s muscle damage, valve damage and pain in chest lead to heart attack or stroke.
Health care industries consider that cardiovascular diseases are the primary reasons to heart attack and human death in the world. That is the reason why most of the researchers are focusing technologies and proposing techniques through ML/DL to predict cardiovascular diseases well in advance. This better prediction is mandatory as for as health care data analysis are concerned [2].
The intelligent techniques through soft computing, artificial intelligence, machine and deep learning helps researchers to extract real patterns and information from the clinical datasets that is helping medical practitioners for taking better predictions and wise decisions.
From the literature survey, it was noticed that the cardiovascular diseases is considered as the prime reasons which leads cause of human death [3-8].
It is also noticed that around 6,10,000 human beings are losing their life due to cardiovascular diseases in US. That is 25% of deaths due to heart diseases. As far as Indian statistical reports concerned, there were predicted that in our population, there were 27% of deaths due to heart diseases as compared with global average 23.5%. This is the common disease for both male and female.
Thus, it is the major issue to be addressed. But however, it seems it is really challenging prediction to predict cardiovascular diseases in advance as it was observed that there were numerous factors are involving for this disease. Pulse rate, LDL, HDL, BP and diabetes are considered as the risk factors. As many risk factors mentioned above causes heart diseases, the healthcare industries and medical practitioners need modern intelligent techniques such as soft computing, artificial intelligence, machine and deep learning with data analytics. This will help researchers to design and develop intelligent model for better prediction [9].
It is noted that heart disease is developing due to stressful life style. Medical practitioners have been diagnosing based on patient’s life style and earlier diagnosis report.
As a result, more researchers are focusing the health sector for better CVD risk in advance.
Artificial intelligence, machine learning and deep learning were introduced better prediction by removing noise and extracting useful information from datasets. These techniques are sued to remove unwanted information from the datasets by applying dimensionality reduction techniques [10]. This will help medical practitioners to take wise decision with better disease prevention treatment. From the literature survey, it was noticed that a few techniques proposed for diagnosing cardiac diseases. It is also noticed that though numerous methods and techniques proposed for this purpose, we need still better classifiers for the best prediction with highest prediction accuracy.
From the literature survey, it was noticed that there were still various intelligent techniques proposed namely pattern recognition, classification and predictive methods for better cardiovascular problems prediction.
It is also noted that ML/DL based classifiers like kNN, DT, SVM, RF, ANN and linear and nonlinear regression techniques to predict cardiovascular diseases.
Materials and Methods
Padmaja, et al., was proposed an efficient machine learning technique, which is proposed for better cardiovascular diseases patterns. It considered as useful method for medical practitioners to understand and predict the actual level of heart diseases.
Geetha, et al., was providing a machine learning technique in association with Artificial Neural Networks (ANN) for predicting cardiovascular diseases patterns prediction. The author used 13 features and predict the patterns [11].
The author implemented and shown this methods performance and noted the efficiency of the classification accuracy 70%.
Gao, et al., has introduced an ML based classifier which is the hybrid model implemented and tried to achieve better classification accuracy. The Kaggle dataset was considered for implementation and analysis. This model ensemble both bagging and boosting approaches.
As both PCA and LR models, it selected required information from datasets for better classification. From the results, it was noticed that the classification accuracy was 98.6%.
Agrahara, et al., has introduced CVD pattern prediction and analyzed effectively. It compares regression, random forest, neural networks, kNN and decision tree. It predicted that the accuracy was 98.02%, better precision and less MSE.
Xiaoming Yuan, et al., designed a fuzzy GBDT technique which combines fuzzy and boosting DT for better classification prediction [12]. It is much suitable to avoid overfitting. It was noticed from the experimental results that it got better classification accuracy.
Mohan, et al., has introduced an effective random forest model called Random Forest Hybrid with a Linear Model (HRFLM). This is the integrated model with linear model and random forest model. The accuracy was predicted and measured as 88.7%. This work considered the dataset named Hungarian from the database UCI.
From the literature survey, it was noticed that the above mentioned IoMT based models were relatively better i.e., we would like to implement and analysis both the Bagging- Fuzzy-Gradient Boosting Decision Tree (FGBDT) and Hybrid Random Forest-Linear Model (HRFLM) as it was predicted as much suitable of IoMT [13]. This paper discusses the characteristics and features of the proposed Ensemble Support Vector Classifier-Weighted Random Forest called ensemble SVC-WRF (E-SVC-WRF) and the existing Bagging-Fuzzy-Gradient Boosting Decision Tree (FGBDT) and Hybrid Random Forest-Linear Model (HRFLM) in the following sections.
Bagging-Fuzzy-Gradient Boosting Decision Tree (FGBDT)
Bootstrap aggregation proposed by Xiaoming Yuan, et al., is used for reducing the DT variance. For training this technique, the features were taken in random pattern. All the predictions were found average and it is considered as the best robust model.
The learning approach is obtaining better area under the curve i.e., AUC and this greatly reduced the variance by bagging technique.
Xiaoming Yuan, et al., utilized the great ML technique GBDT. The GBDT diagram is as shown in the Figure 1. From the experimental report, it is clearly noticed that it reduced loss function and achieved better accuracy which is demonstrated in the Equation 1.

Figure 1: Schematic diagram of the GBDT Technique.
As shown in the equation 1, the weighted coeffients are a,b,c….ρ. The F(x) is the sum of all trees outcomes make better conclusion.
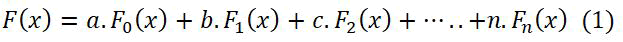
This work was found to be best technique for the better distribution in ML techniques. It is able to execute and process different data types to predict better disease patterns.
The author has implemented this classifier in parallel which is able to predict patterns in parallel [14]. Thus the complexity is reduced in the datasets. It addresses the overfitting issues as well.
Fuzzy-GBDT: Fuzzy logic integrates GBDT algorithm
Data fuzzification: As we know, if we needed better classification accuracy that will lead to more process and data complexity. When executing diagnosis processes, we can notice that the prediction report might be the same for different patients whereas all the attributes are common.
This might be lead to complexity. This issue was solved in this model as fuzzy logic was employed. The datasets used under hierarchical model and narrates degree for each and every attributes.
As this model employs membership function, its complexity is much reduced. The membership function was shown in the Figure 2.

Figure 2: Effect of different values α in membership.
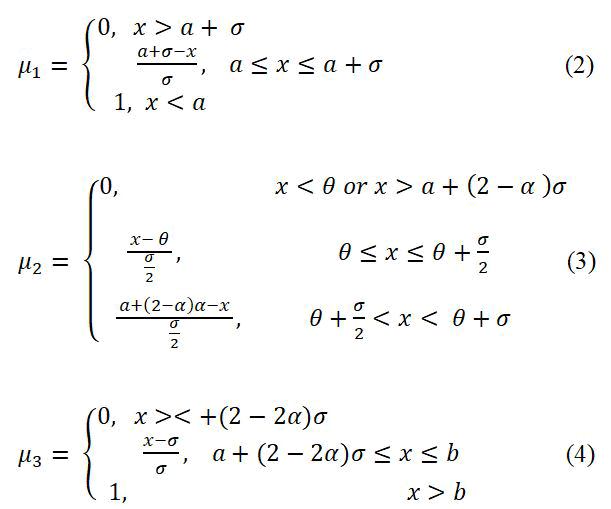
The fuzzification with different slope is shown in the Figure 2. In the data samples, the age distribution is from 0 to 90. The slope can be correlated with age by adjusting α and the data set has 14 attributes.
Hybrid Random Forest-Linear Model (HRFLM)
Mohan, et al., has introduced an effective random forest model called random forest Hybrid with a Linear Model (HRFLM). This is the integrated model with linear model and random forest model.
The accuracy was predicted and measured as 88.7%. This work considered the dataset named Hungarian from the database UCI. As shown in the Figure 3, the HRFLM considers 14 attributes such as age, gender, CP, bps, FBS, rest ECG, slope, CA, THAL.
These features took from UCI dataset is feeding to linear method in association with random forest is feed again to HRFLM. This will predict the pattern based on the input and will be classified. As mentioned, the classification accuracy was 88.7%.

Figure 3: Heart disease prediction with HRFLM.
HRFLM approach was used for improving the performance by hybrid both the random forest and logistic regression which is called as linear regression medel. It proves to be the better classifier for performing classification accuracy with relatively less error. There are three steps in performing the hybrid technique.
• Finding out the output probabilities of each model. To implement this Mohan, et al., using the pred-proba function which gives the target probability in the sequesnce list form. As we know, for each category, the unique probability levels are fixed with target variable.
• With the help of log loss function, finding the optimized weight that perfectly combines the two models which has low classification error rate. Log loss function is a metric which considers prediction uncertainty based on input features and labels.
• Using the optimized weight from the above step combining the two models with the help of weighted average and then performing the prediction. From the results, it was noticed that it achieved better classification accuracy as compared with other classifiers.
Algorithm
Input dataset
For ∀ attribute-features:
For each attributed sampling:
Process and run DT.
Classify patterns and features f1,f2…fn of dataset.
Get the number of leaf nodes ln1, ln2,…lnn. Spilit
the dataset D into sd1, sd2,… sdn.
Output: Patterns partitions
For ∀ features:
Partition R(p1,p2,p3…pn)
Classify the datasets with cluster.
Output: C(R(p1,p2,…pn)
For ∀ features error minimization:
Min(C1(R1(p1,p2,…pn).
Min(C2(R1(p1,p2,…pn).
Min(Cn(R1(p1,p2,…pn).
Output: Attributed-features with classified features F(d1,d2,d3,..dn).
Extracted features
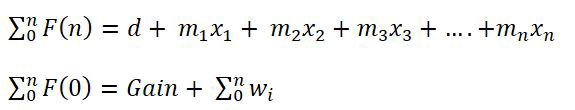
Proposed an Ensemble Support Vector Classifier- Weighted Random Forest called Ensemble SVCWRF (E-SVC-WRF)
In this proposed model, this research work introduced Ensemble Support Vector Classifier-Weighted Random Forest called ensemble SVC-WRF (E-SVC-WRF). In other words, the support vector classifier is employed for selecting and classifying diseases patterns by optimizing hyperplane and weighted random forest is employed for predicting patterns for cardiovascular disease diagnosis based on patterns classification. Further, the score of weighted random forest can be calculated by repeating average weights for different sizes of clusters.
As support vector classifier is designed as the non-linear model by introducing RBF kernel function for patterns, it removes irrelevant patterns, noise, and redundancy as well which select the features and patterns effectively. As this model effectively reducing data set size, the prediction accuracy is better than existing model. The working processes of the proposed model is shown in the Figure 4.

Figure 4: Proposed model: E-SVC-WRF.
Algorithm
Input dataset
For ∀ attribute-features:
For each attributed sampling:
Process and run DT.
Classify patterns and features f1,f2…fn of dataset.
Get the number of leaf nodes ln1, ln2,…lnn.
Spilit the dataset D into sd1, sd2,… sdn.
Output: SVC based patterns partitions with sizes and weightsAVG
For ∀ features do.
Partition R(p1,p2,p3…pn).
Classify the datasets with clusters.
Classify the clusters with sizes and weight scores.
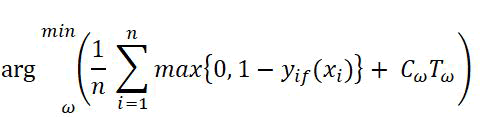
Output: C(R1(p1,p2,…pn) R2(p1WC,p2WC,p3WC, … pnWC
For ∀ features error minimizations do.
Min(C1(R1(p1,p2,…pn).
Min(C2(R2(p1WC,p2WC,p3WC, … pnWC).
Min(C2(R1(p1,p2,…pn).
Min(C2(R2(p1WC,p2WC,p3WC, … pnWC).
Min(Cn(R1(p1,p2,…pn).
Min(Cn(R2(p1WC,p2WC,p3WC, … pnWC).
Output: Attributes features with classified attributes F(d1,d2,d3,..dn).
Extracted features Fo (training)
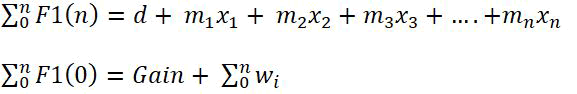
Extracted features F1 (testing)
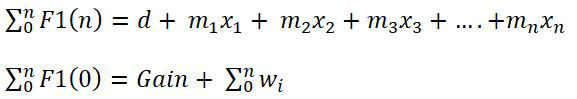
Output: Patterns diagnosis.
Experimental setup
The dataset from repository of machine learning UCI was downloaded. The heart disease dataset namely Switzerland, Hungary, Cleveland were used for performance analysis. The downloaded dataset has 303 records and there were 76 attributes. We considered 14 attributes for cardiovascular patterns prediction.
The datasets were taken from which is used for analysing the above mentioned classifiers. The experimental set up is created in with BioWeka and simulations are conducted by this project work by using the clever land data sets, master MER. This was taken from the above mentioned link for study.
As mentioned earlier, this project work has developed with the VC++ professional 2022 and MSVC tool that is developed for extracting and validating various patterns of heart diseases. The standardized and cleaned dataset was feeding to BioWeka to analyze the identified models. Simulations are carried out to evaluate the performances and classification and prediction abilities of the above listed our proposed classifiers.
This work considered 10 different data sets grouped together for predicting cardiovascular disease patterns, and each group has 50,000 samples out of 5,00,000 samples used for prediction analysis of the existing model. The experiments were executed again and again for measuring the efficiencies of the classifier.
The performances of the proposed classifier Ensemble Support Vector Classifier-Weighted Random Forest called ensemble SVC-WRF (E-SVC-WRF and the identified two classifiers Bagging-Fuzzy-Gradient Boosting Decision Tree (FGBDT) and Hybrid Random Forest-Linear Model (HRFLM) were implemented and carefully analyzed its performances during training and testing processes in terms of sensitivity, specificity, accuracy, FScore and average processing time (ms).
Results and Discussion
As shown at the Figure 5, execution processes of the proposed E-SVC-WRF and the experimental set up is created in with BioWeka and simulations are carried out with clever land data sets, Master MER.

Figure 5: Execution processes of the proposed E-SVC-WRF.
The proposed Ensemble Support Vector Classifier-Weighted Random Forest called Ensemble SVC-WRF (E-SVC-WRF was trained effectively with the datasets and tested to measure its prediction accuracy. The performance metrics sensitivity, specificity, and FScore were calculated by repeating experiments which are shown in the Figures 6-8.

Figure 6: Performance analysis-sensitivity of E-SVC-WRF during testing.
From the Figures, it was noticed that the proposed model was predicting the patterns effectively as compared with the exiting models Bagging-Fuzzy-Gradient Boosting Decision Tree (FGBDT) and Hybrid Random Forest-Linear Model (HRFLM).

Figure 7: Performance analysis-specificity of E-SVC-WRF during testing.

Figure 8: Performance analysis-FScore of E-SVC-WRF during testing.
The proposed model is achieving better classification and prediction in terms of true positive rate and true negative rate as well.
From the Figure 9, it was observed that during training and testing processes, the proposed ESVC-WRF is achieving the best classification accuracy. It is also noted from the experimental report that the proposed model has less time complexity.

Figure 9: Performance analysis-accuracy of E-SVC-WRF during testing.
Conclusion
The recently proposed Bagging-Fuzzy-Gradient Boosting Decision Tree (FGBDT) and Hybrid Random Forest-Linear Model (HRFLM) Classifiers were Studied thoroughly and implemented carefully to analyze its performances during training and testing processes in terms of prediction accuracy, precision, sensitivity, specificity, FScore and average processing time (ms). From the experimental results, it was noticed that the Hybrid Random Forest-Linear Model (HRFLM) is performing well during training and testing processes in terms of prediction accuracy, precision, sensitivity, specificity, FScore and average processing time (ms) as compared with Bagging-Fuzzy-Gradient Boosting Decision Tree (FGBDT). However, it is predicted that the Hybrid Random Forest-Linear Model (HRFLM) is not suitable for better prediction when datasets have more different patterns with very less dissimilarities. To maximize classification and prediction accuracy better, this work is proposed an efficient Ensemble Support Vector Classifier- Weighted Random Forest called Ensemble SVC-WRF (ESVC- WRF) and implemented for analysis. From the experimental results, it was noticed that the proposed Ensemble Support Vector Classifier-Weighted Random Forest called Ensemble SVC-WRF (E-SVC-WRF) is performing well as compared with Hybrid Random Forest- Linear Model (HRFLM) and Bagging-Fuzzy-Gradient Boosting Decision Tree (FGBDT) in terms of prediction accuracy, precision, sensitivity, specificity, FScore and average processing time (ms).
References
- Garate-Escamila AK, El Hassani AH, Andres E. Classification models for heart disease prediction using feature selection and PCA. Inform Med Unlocked. 2020;19:100330.
- Lakshmanarao A, Swathi Y, Sundareswar PS. Machine learning techniques for heart disease prediction. Forest. 2019;95:97.
- Abdellatif A, Abdellatef H, Kanesan J, Chow CO, Chuah JH, Gheni HM. An effective heart disease detection and severity level classification model using machine learning and hyperparameter optimization methods. IEEE Access. 2022;10:79974-79985.
- Agrahara A. Heart disease prediction using machine learning algorithms. Int J Sci Res Comp Sci Eng Infor Tech. 2020;6:137-149.
- Alotaibi F. Implementation of machine learning model to predict heart failure disease. Int J Adv Comput Sci Appl. 2019;10:261-268.
- Eason G, Noble B, Sneddon IN. On certain integrals of lipschitz-hankel type involving products of bessel functions. Philos Trans Royal Soc A. 1955;247:529-551.
- Gao XY, Amin Ali A, Shaban Hassan H, Anwar EM. Improving the accuracy for analyzing heart diseases prediction based on the ensemble method. Complexity. 2021;1-10.
- Ahmad GN, Fatima H, Ullah S, Saidi AS. Efficient medical diagnosis of human heart diseases using machine learning techniques with and without GridSearchCV. IEEE Access. 2022;10:80151-80173.
- Mohan S, Thirumalai C, Srivastava G. Effective heart disease prediction using hybrid machine learning techniques. IEEE access. 2019;7:81542-81554.
- Geetha S, Devi CP, Kalaivani V, Haritha CJ, Preetha G. Prediction techniques of heart disease and diabetes disease using machine learning. Turk J Comp Math Edu. 2021;12:3316-3325.
- Padmaja B, Srinidhi C, Sindhu K, Vanaja K, Deepika NM, Patro EK. Early and accurate prediction of heart disease using machine learning model. Turk J Comp Math Edu. 2021;12:4516-4528.
- Goel S, Deep A, Srivastava S, Tripathi A. Comparative analysis of various techniques for heart disease prediction. Int Conf Infor Syst Comp Net. 2019;88-94.
- Hernandez VA, Monroy R, Medina-Perez MA, Loyola-Gonzalez O, Herrera F. A practical tutorial for decision tree induction: Evaluation measures for candidate splits and opportunities. ACM Comp Surv. 2021;54:1-38.
- Yuan X, Chen J, Zhang K, Wu Y, Yang T. A stable AI-based binary and multiple class heart disease prediction model for IoMT. IEEE Trans Indus Infor. 2021;18:2032-2040.


 The Annals of Medical and Health Sciences Research is a monthly multidisciplinary medical journal.
The Annals of Medical and Health Sciences Research is a monthly multidisciplinary medical journal.